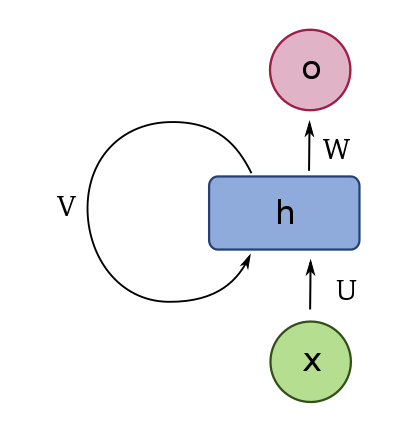
In this article, I will discuss the chance of making a profit by trading small-cap stocks. The brief conclusion is that further research, including collecting more data, is needed to put this strategy into reality. Note that the priority purpose of writing this article is to show my ability of Python programming, web-scraping, and building RNN models rather than introducing a promising trading strategy. I would like the readers to understand this point and read the following. Though the trading strategy itself is very rough, the code for scraping and building RNN models would be useful for some.
Introduction
In this article, I want to build a model that predicts the stock price movement based on comments about each company’s business provided by Shikiho. It may be a natural assumption that stocks with a positive business outlook tend to perform better. To test this hypothesis, I will collect the Shikiho data and build a recurrent neural network model.
Preparing a Dataset
What is “Shikiho”?
In this article, I will use the data from “Shikiho”, which contains extensive data for every single listed company in Japan. Here, I will focus only on a description of each company, which covers how well their business is, the future outlook, issues that may arise, their business environment, and so on. I believe this data is very useful because it covers all the listed companies regardless of the market cap. In general, the so-called analysts only cover large-cap or middle-size stocks that have enough liquidity for their major clients, institutional investors, to take a certain amount of position with low cost. So, the small-caps are abandoned, having limited chances to get their business recognized by investors. This background explains why I believe Shikiho is useful. They provide homogeneous analysis on all the listed companies in Japan, and therefore, we may find out great companies to invest in.
Take a look at an example of Toyota, the most dominant car manufacturer in Japan.
【上向く】世界販売1029万台(4%増)に下振れ。9~10月計画比60万台超減産影響。好採算のSUV拡大と販売奨励金抑制で資材高かわす。円安追い風。利益反発。23年3月期も内外で新型車寄与。連続増益。
([Improving] Global sales fell to 10.29 million units (up 4%). Impact of production cuts of more than 600,000 units compared to the September-October plan. Dodge high materials by expanding profitable SUVs and curbing sales incentives. Weaker yen positively affected. Profit rebound. New models are to contribute both domestically and internationally in the fiscal year ending March 2023. Profit increases continuously.)
【挽回】今期生産計画900万台達成は22年1~3月に過去最高水準の月産80万台後半必要。部品各社の人員確保課題。米国で電池工場25年に稼働。電動車拡販に対応。
([Recovery] Achieving the production plan of 9 million units for this term requires a record high level of monthly production of 800,000 units in the latter half of January to March 2022. Securing personnel for parts companies is an issue. A battery factory in the United States will start operation in 2025 that supports sales expansion of electric vehicles.)
As you can see, it explains their current business condition, what features may affect the company in the near future, etc.
How can I collect this data?
Shikiho has been published quarterly and you can buy one at the bookstore. So, should I buy one and type everything manually? Well, maybe my life is not long enough to do that. One possible idea would be scraping. Some brokerages in Japan provide Shikiho data for their clients for free on their website to help their clients make decisions on investment. (and make their clients place an order and get the brokerage fee!) I have an account at one of these brokerages, which is Daiwa Securities, and so, write some code and get the data automatically. I am a data scientist. I hate the manual work of copy and paste. Simple repetitive tasks must be automated!!
Preparation
Before getting into the coding for scraping, we need to do some preparations. First, we need to get a list of listed companies. In the scraping part, we will make a query using a unique 4-digit code for each company. This code is similar to tickers in the stock market in the US, like AAPL and TSLA for Apple and Tesla, respectively. We can download the list from this link. Note that this list is provided by JPX, Japan Exchange Group, the company running Tokyo Stock Exchange. Though most of the Japanese companies are listed on the Tokyo Stock Exchange, there are few companies listed on the other exchanges, and Shikiho covers these companies, too! Yet, here, I will deal with only the stocks listed on the Tokyo Stock Exchange. The second thing is downloading a driver for scraping. As we will use selenium for scraping, you need to prepare a certain driver that works on your browser choice. If you are using Chrome like me, you can find a driver here. So, the code for this section is as follows.
# Importing the libraries
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import pickle
from tqdm import tqdm_notebook as tqdm
import pandas as pd
import lxml.html
import os
# Setting the path to the driver.
driver_path = '.../chromedriver'
# This is the login page of Daiwa clients.
url = 'https://www.daiwa.co.jp/PCC/HomeTrade/Account/m8301.html'
# The following three are required to login to the personal account.
shiten = 'xxx'
account = 'xxxxxx'
password = 'xxxxxxxxxx'
# Read the excel downloaded from the JPX website
TSE_list = pd.read_excel("data_e.xls")Focusing only on the small-cap stocks
In this experiment, we will be focusing only on small caps. This is because large companies are covered by professional analysts and there is a lot of reports available. By contrast, for small companies, there are fewer reports, and this may make the impact of Shikiho as an information provider, significant. Looking into the TSE_list, you will see that the stocks are categorized into 6 classes by size. (See “Size Code” and “Size” rows) So, we will remove the companies classified as TOPIX Core30, TOPIX Large70, and TOPIX mid400. In addition, the listed investable is not limited to companies. We also have ETFs, REITs, etc. but here, we again focus only on companies that are actually running their business. Lastly, I excluded the foreign companies listed on Tokyo Stock Exchange.
# Focusing on small caps.
scraping_list = TSE_list.loc[TSE_list["Size Code (New Index Series)"].isin([6, '-', 7])]
# Removing ETFs, REITs, foreign companies, etc.
section_use = ['First Section (Domestic)', 'JASDAQ(Standard / Domestic)', 'JASDAQ(Growth/Domestic)', 'Mothers (Domestic)', 'Second Section(Domestic)']
scraping_list = scraping_list.loc[scraping_list["Section/Products"].isin(section_use)]
# Storing only 4-digit codes for For-loop operation in the following.
scraping_codes = scraping_list["Local Code"].valuesLet’s do scraping!
Here comes the fun part! Scraping! We begin with logging in to the personal account and going to the page where we can get the Shikiho data. The source of this webpage is straightforwardly written and easy to understand. There are no embedded js files. A bit of knowledge of HTML does the job.
# We will wait to read the page up to the time setting here.
wait_time = 15
driver = webdriver.Chrome(driver_path)
driver.get(url)
WebDriverWait(driver, wait_time).until(EC.presence_of_all_elements_located)
# Filling the data for logging in.
driver.find_element_by_name('@PM-1@').send_keys(shiten)
driver.find_element_by_name('@PM-2@').send_keys(account)
driver.find_element_by_name('@PM-3@').send_keys(password)
# Then, click the "LOGIN" button.
driver.find_element_by_xpath("//input[@type='submit']").click()
# Going to the Shikiho page.
WebDriverWait(driver, wait_time).until(EC.presence_of_all_elements_located)
driver.find_element_by_link_text('マーケット').click()
WebDriverWait(driver, wait_time).until(EC.presence_of_all_elements_located)
driver.switch_to_frame('qcmain')
driver.find_element_by_id('qcdw_menu23').click()
WebDriverWait(driver, wait_time).until(EC.presence_of_all_elements_located)
driver.find_element_by_id('qcdw_menu34').click()The obtained data will be stored in the list shikiho. Since the entire procedure takes over two hours, and errors often occur like the page not responding and the browser crashing, I first check if a half-done work exists.
file_name = "shikiho_22_01.txt"
# If the half-done work exists,
if os.path.exists(file_name):
shikiho = pickle.load(open(file_name, 'rb'))
# Will do only for the remaining codes.
scraping_codes = scraping_codes[scraping_codes > shikiho[-1][0]]
else:
# Setting a new empty list.
shikiho = []Now, time to run the following code. All I did was drink a cup of coffee and watch the display on which the data is scraped magically!
# Loop over all the codes.
for code in tqdm(scraping_codes):
add = []
add.append(code)
driver.find_element_by_name('txtCode').clear()
driver.find_element_by_name('txtCode').send_keys(str(code))
# This sleep is crucially IMPORTANT not to place burden on the server.
sleep(1)
driver.find_element_by_name('submit').click()
WebDriverWait(driver, wait_time).until(EC.presence_of_all_elements_located)
root = lxml.html.fromstring(driver.page_source)
exist = root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"]')
if bool(exist)==False:
continue
# We need to see different parts on the source for some companies. This is the given setting of Daiwa's website.
if root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"][2]/tbody/tr[7]/th')[0].text_content in ['【本店】','【本社】','【本部】','【持株会社本社】']:
i = 5
else:
i = 6
# Before storing, do some trimming.
feature = root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"][2]/tbody/tr[' + str(i) + ']/th')[0].text_content().replace('\u3000','').replace('【','').replace('】','').strip()
add.append(feature)
feature = root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"][2]/tbody/tr[' + str(i) + ']/td')[0].text_content().strip()
add.append(feature)
feature = root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"][2]/tbody/tr[' + str(i+1) + ']/th')[0].text_content().replace('\u3000','').replace('【','').replace('】','').strip()
add.append(feature)
feature = root.xpath('//table[@class="tblcol tbltp1 tblhover5lines"][2]/tbody/tr[' + str(i+1) + ']/td')[0].text_content().strip()
add.append(feature)
shikiho.append(add)
print('finish!')
driver.close()
pickle.dump(shikiho,open(file_name, 'wb'))This is the end of the scraping part! Let’s move on to the model building part!
Preprocessing
What kind of preprocessing is needed?
Let’s check our goal again. The purpose is to make a model that predicts the stock price performance based on Shikiho’s description. So, in this preprocessing part, I will prepare the stock return data, and transform the description data to be ready to use pre-trained word vectors.
Stock returns
We want to examine if Shikiho can be a useful predictor for stock price performance. Thus, we need to compare the stock price just before the Shikiho was published and the stock price a few days or weeks later. In this article, because the latest version of Shikiho was released on December 15, 2021, I use the stock price data on December 14, 2021, and February 7, 2022. This range may be too long or too short and I would admit that there is room to discuss further, I will work on these dates anyway. I used data that are available here.
# Concatenate two dataframes.
ret_df = pd.merge(start_df[["銘柄コード", "終値", "配当落日", "配当"]], end_df[["銘柄コード", "終値"]], how="outer", on="銘柄コード").dropna(axis=0)
ret_df.columns = ["code", "last0", "div_date", "dividend", "last1"]
# Drop the stock that price data is missing. Note that last means the closing price.
ret_df = ret_df[(ret_df["last0"] != ' ') & (ret_df["last1"] != ' ')]
ret_df = ret_df.astype({"code": int, "last0": float, "div_date": object, "dividend": float, "last1":float})
# This part is a little technical. What I am doing here is adding the dividend for stocks that pay dividend during the period.
# When a company pays out a dividend, the stock price decreases accordingly.
# If you follow only the stock price, this can be treated as a loss.
# But this is not a loss because you will receive the dividend, and this is why I add back the dividend to the stock price.
ret_df["last1"] = ret_df["last1"] + (ret_df["div_date"]=="2022/1/28") * ret_df["dividend"]
# We often use log return to measure the performance.
ret_df["return"] = np.log(ret_df["last1"] / ret_df["last0"])
# Normalize the log return to feed it to the regression model.
ret_df["norm_return"] = (ret_df["return"] - ret_df["return"].mean()) / ret_df["return"].std()Mecab (word-separation)
One of the major differences between English and Japanese is that the words in a sentence are separated by spaces in English while it is not in Japanese. When you are dealing with languages like Japanese, you are required to do additional preprocessing of separating the words. One of the libraries to perform this task is Mecab. In the following code, I do the word-separation using Mecab.
# First, load the useful libraries for this part.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import pickle
from gensim.models.word2vec import Word2Vec
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.utils import to_categorical
# Install the Mecab dictionary.
!brew install mecab-ipadic
# Install Mecab and import
!pip3 install mecab-python3
import MeCab
# Read the data from the scraping part.
shikiho = pickle.load(open("shikiho_22_01.txt", 'rb'))
# Define a fuction for word-separation and apply it on our dataset.
def parse_text(array):
tagger = MeCab.Tagger('-Owakati')
parsed = [array[0], tagger.parse(array[1])[:-2], tagger.parse(array[2])[:-2], tagger.parse(array[3])[:-2], tagger.parse(array[4])[:-2]]
return parsed
parsed_shikiho = [parse_text(array) for array in shikiho]
parsed_shikiho_df = pd.DataFrame(parsed_shikiho, columns=['code','f1','f2','f3','f4'])
parsed_shikiho_df["concat"] = parsed_shikiho_df["f1"] + " " + parsed_shikiho_df["f2"] + " " + parsed_shikiho_df["f3"] + " " + parsed_shikiho_df["f4"]
# Merge with the return data.
data_df = pd.merge(parsed_shikiho_df, ret_df, how="inner", on="code")Pre-trained word vector
Then, we prepare the pre-trained word vector. As there are many of them on the Internet, I decided to use the one here. The size of the vector is relatively small, with only 50 values for each word.
# Use Tokenizer in Keras.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(data_df['concat'].values.tolist())
# The number of unique words that shown in Shikiho data.
word_index = tokenizer.word_index
# Read the pre-trained word vector.
embedding_model = Word2Vec.load(".../latest-ja-word2vec-gensim-model/word2vec.gensim.model")
# For each word, assign the corresponding word vector.
embedding_matrix = np.zeros((len(word_index)+1, 50))
for word, i in word_index.items():
if word in embedding_model.wv.index2word:
embedding_matrix[i] = embedding_model[word]
description = data_df["concat"].values
# Represent the Shikiho data with numbers that work as an index to access the word vector.
description = tokenizer.texts_to_sequences(description)Though the lengths of the Shikiho description are almost the same, we have to determine exactly how many words to feed into the model. Let’s see what we have now.
plt.hist([len(desc) for desc in description], bins=50)
plt.grid()
plt.show()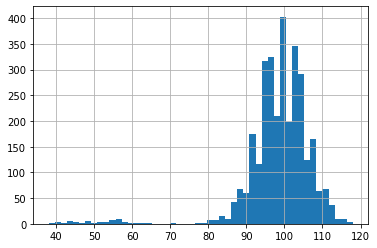
We can see that the lengths are mostly centered around between 90 and 110. In the following, I will feed 100 words into the model. So, for descriptions longer than 100, just cut the tail, and for shorter ones, pad with 0. Then, I split the data into the training set and the test set.
maxlen = 100
description = sequence.pad_sequences(description, maxlen=maxlen, value=0.0)
Xtr, Xts, ytr, yts = train_test_split(description, data_df["norm_return"].values, test_size=0.15)Building RNN models
Using pre-trained word vector
In this first section, we will train a model using the downloaded word vector. One possible implementation is the following.
# Import the libraries.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Dropout, Activation
from tensorflow.keras.layers import Embedding, Flatten, LSTM, Bidirectional, BatchNormalization, LeakyReLU
from tensorflow.keras import regularizers
# Setting the RNN model.
inputs = Input(shape=(maxlen,))
x = Embedding(len(word_index)+1, embedding_matrix.shape[1], weights=[embedding_matrix], input_length=maxlen, trainable=False)(inputs)
x = LSTM(8)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Dense(8)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
outputs = Dense(1, activation='linear')(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='adam')
model.summary()
# Fitting on the training set.
history = model.fit(Xtr, ytr, batch_size=128, epochs=30, validation_data=(Xts, yts))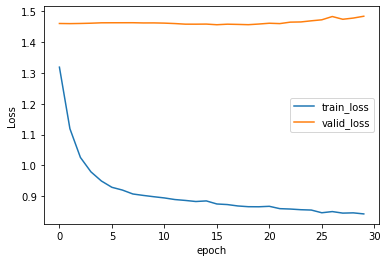
Unfortunately, we got the typical overfitting. The more epochs to train, the training loss is decreasing but the validation loss is even increasing. I would point out that the loss larger than 1.0 is terrible. We are using mean squared error and the log return was normalized. So, if we stop doing complicated things and predict 0.0 for any inputs, the loss should be around 1.0. The result we got here is worse than this lazy predictor.
RNN without pre-trained word vector
I also share the code not using the pre-trained word vector. Namely, the word vector is also learned from the data.
inputs = Input(shape=(maxlen,))
x = Embedding(len(word_index)+1, 8)(inputs)
x = LSTM(8)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Dense(8)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
outputs = Dense(1, activation='linear')(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='adam')
model.summary()
history = model.fit(Xtr, ytr, batch_size=128, epochs=30, validation_data=(Xts, yts))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'valid_loss'], loc='best')
plt.savefig("wo_pretrained.png", bbox_inches="tight")
plt.show()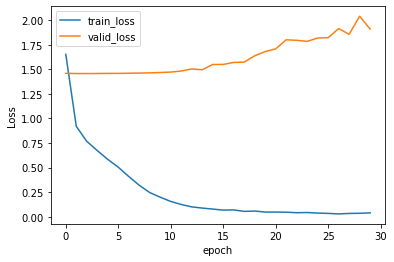
Again, we got overfitting, and this time, the training error became very low. This suggests that we need more data. This happens because the number of words that are shown in the Shikiho is too large compared with the number of stock return data. What the model is doing here is “Okay, I see this certain word in the description, then output this value”, and it may not be related to the context of the description.
Summary
So far, we looked through how we can collect a bunch of data using web scraping, what sort of preprocessing is required for building a language model, especially Japanese language where all the words are not separated. Finally, we saw how to build an RNN model using Keras. Although the result is not satisfying enough to put this strategy into reality, it can be a good start to investigate further. There are many possible approaches to improve this model. What if we use different RNN cells? What happens if we use the bidirectional model? What if we choose a different time span to compute the return? What if focusing on the changes between the latest Shikiho and the previous version?

コメント
I am in fact glad to glance at this weblog posts which consists of tons of valuable information, thanks for providing these kinds of information.
An impressive share! I have just forwarded this onto a colleague who has been doing
a little research on this. And he in fact bought me lunch simply
because I stumbled upon it for him… lol. So allow me to reword
this…. Thanks for the meal!! But yeah, thanx for spending time to discuss
this subject here on your web site.
There’s certainly a lot to know about this subject.
I love all of the points you made.
Good day! This is my 1st comment here so I just wanted to give a
quick shout out and say I genuinely enjoy reading your posts.
Can you suggest any other blogs/websites/forums that deal with the
same topics? Thanks a ton!
Right here is the perfect webpage for anybody who wishes to understand this topic. You know so much its almost hard to argue with you (not that I really will need toÖHaHa). You definitely put a fresh spin on a subject which has been written about for decades. Wonderful stuff, just excellent!
Posting yang bagus, saya telah membagikannya dengan teman-teman saya.